
System Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
1 Peking University · 2 PKU-PsiBot Joint Lab · 3 Nanyang Technological University · 4 PsiBot
1 Peking University · 2 PKU-PsiBot Joint Lab · 3 Nanyang Technological University · 4 PsiBot
Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware–algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability.
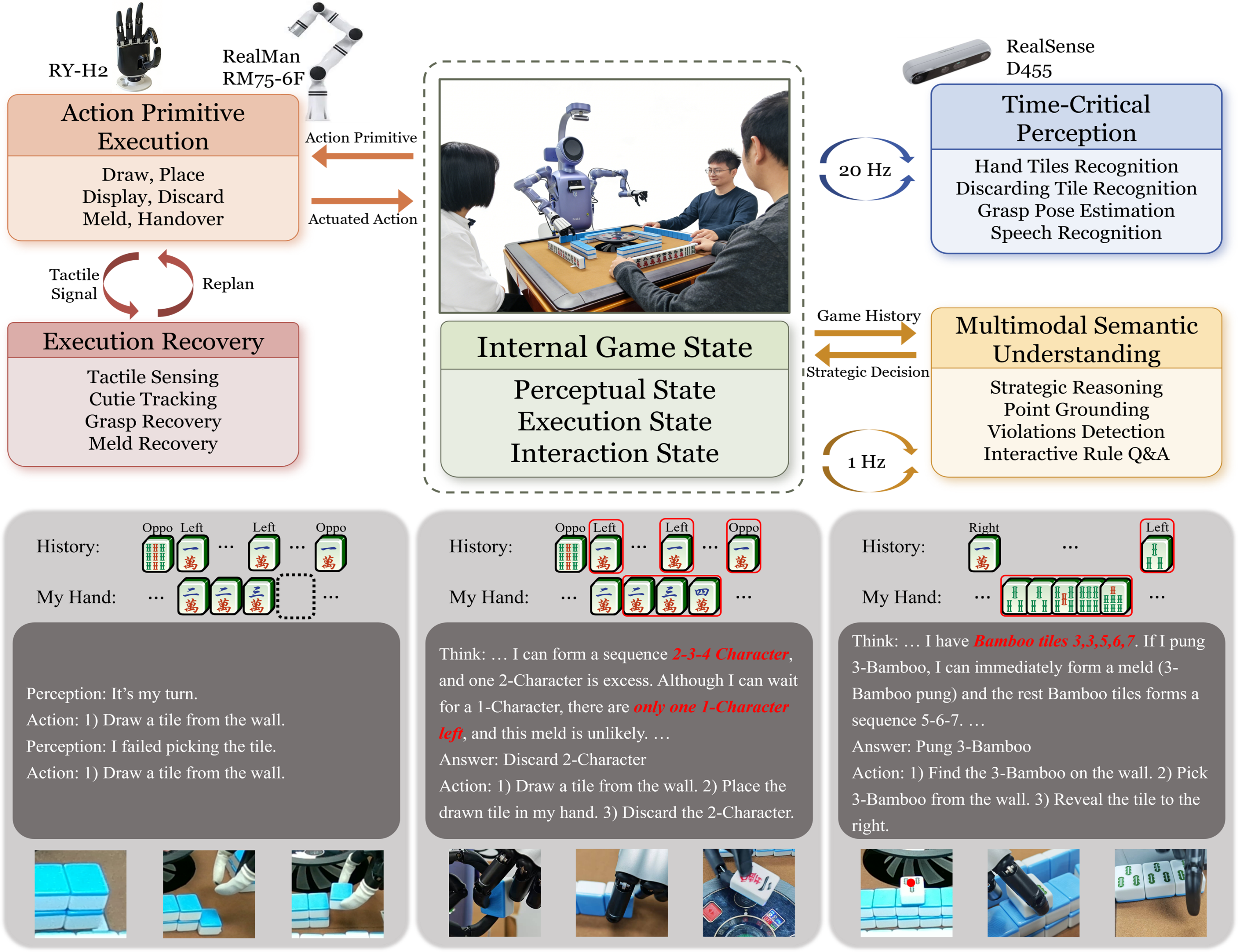
The robot plays complete Mahjong games with real human participants in both lab and public exhibition environments.
Real-world deployment: multi-human long-horizon Mahjong gameplay with the robotic system.
Evaluated across 122 complete games with real human players, in both laboratory and public deployment settings.
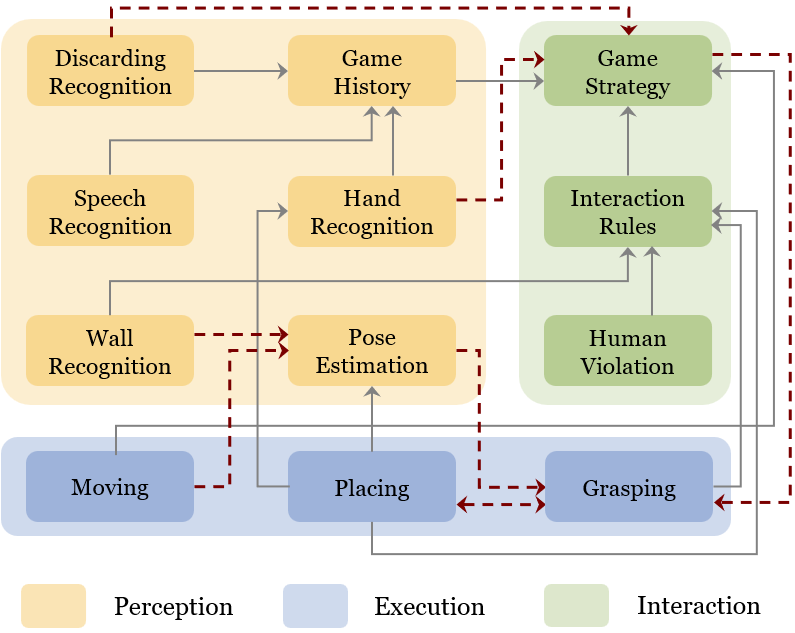
Four key design principles enable the robot to maintain executable state consistency across a full game of Mahjong.
A fine-tuned VLM (Qwen2.5-VL-7B) handles high-level strategy, rule interpretation, and turn validation. Latency-sensitive tasks — tile detection (YOLO, 15 ms), segmentation (SAM), and pose estimation (FoundationPose) — are handled by dedicated modules. This prevents cross-component interference and keeps failure modes interpretable.
Every action (draw, discard, place, meld) is a guarded state transition: precondition check → perceptual grounding → motion execution → tactile/force post-verification → state update. State is only committed after physical confirmation, preventing premature updates that cascade into downstream errors.
Tactile sensing detects incomplete grasps. On failure, the target tile is re-localized via segmentation tracking (Cutie) and a new grasp pose is estimated — all without modifying internal state variables. Execution failures are converted from irreversible state corruption into recoverable events.
VLM-based reasoning conditioned on maintained turn state detects two key violations: out-of-turn play and unauthorized tile inspection. Events are logged and surfaced to players without forcibly interrupting gameplay, preserving human authority while maintaining transparency about potential inconsistencies.

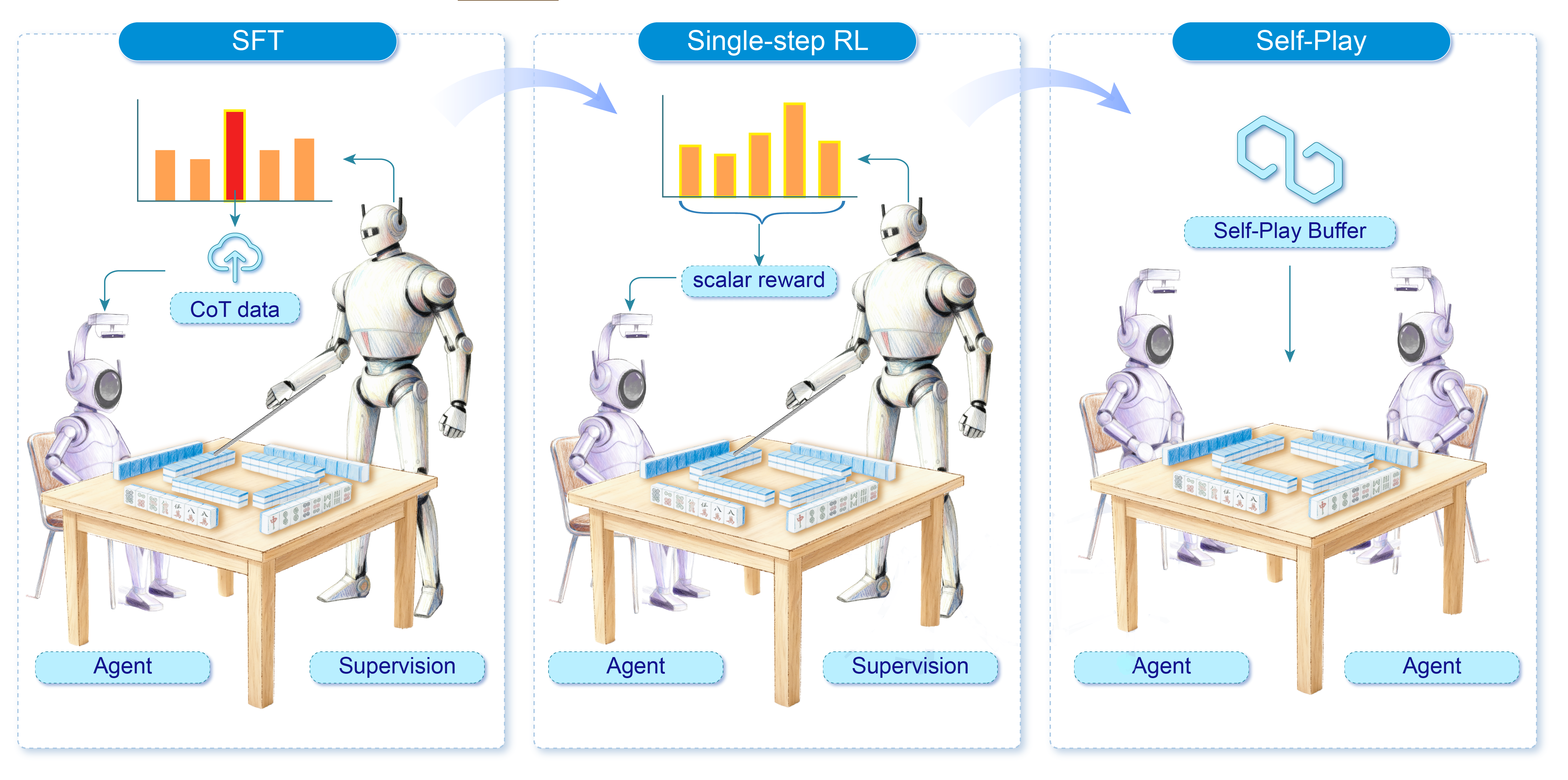
A three-stage training pipeline distills game knowledge and improves decision quality through self-play.
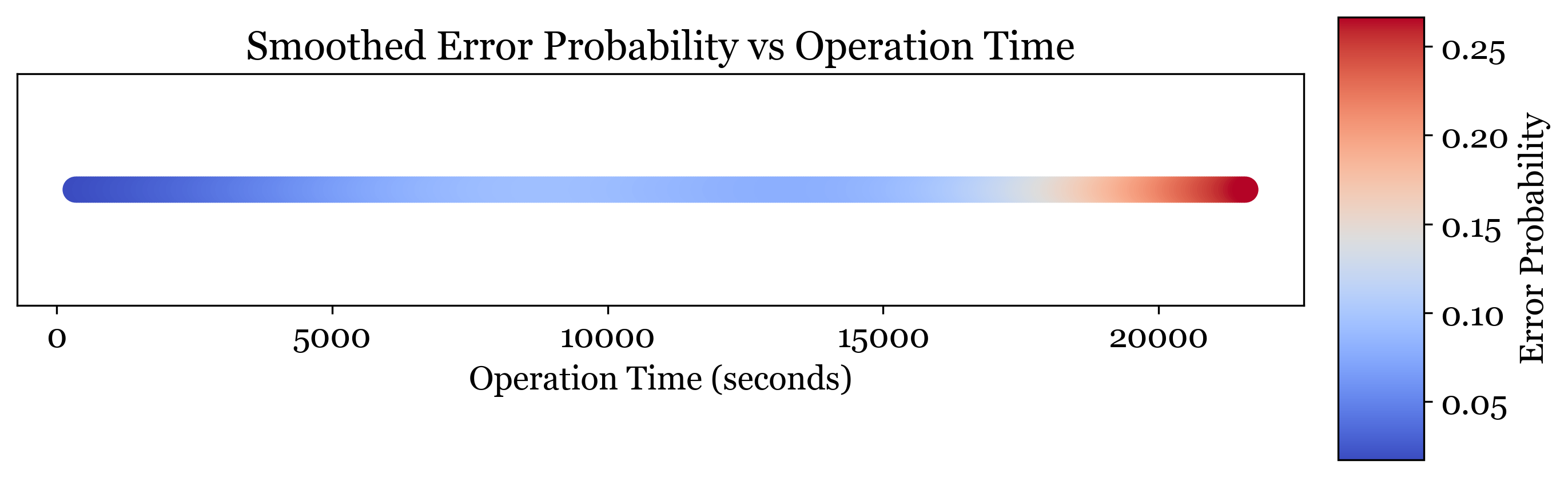
Empirical measurements exposing how failures propagate and how hardware limits system reliability over time.
| Task | VLM | Specialized (YOLO / DINO) |
|---|---|---|
| Tile recognition accuracy | <94.3% (per-tile) | 98.9% (YOLO, per-image) |
| Inference latency | ≥380 ms | 15 ± 2 ms (YOLO) |
| Unauthorized inspection (P/R) | 0.967 / 0.989 | 0.956 / 0.960 (DINO) |
| Turn attribution (P/R) | 0.937 / 0.976 | 0.949 / 0.931 (DINO) |
| Cross-identity error | 0% | 3.0% (DINO) |
Fast physical perception requires dedicated lightweight modules; context-dependent interaction reasoning benefits from VLM semantics. The architecture reflects empirical partitioning, not arbitrary modularity.
If you find this work useful, please cite our paper:
@misc{zhao2026system,
title={System Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games},
author={Guangyu Zhao and Ceyao Zhang and Chengdong Ma and Tao Wu and Yiyang Song and Haoxuan Ru and Yifan Zhong and Ruilin Yan and Lingfeng Li and Ruochong Li and Yu Li and Xuyuan Han and Yun Ding and Ruizhang Jiang and Xiaochuan Zhang and Yichao Li and Yuanpei Chen and Yaodong Yang and Yitao Liang},
year={2026},
eprint={2603.25405},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.25405},
}